Regra de Associação
Relacionam a presença de um conjunto de itens (antecedente) com a ocorrência de outro conjunto (consequente), mostrando como certos elementos tendem a aparecer juntos.
Uma regra de associação é um padrão do tipo X → Y, que mostra como certos itens ou comportamentos ocorrem juntos.
Exemplo: “clientes que compram pão também compram leite.”
Essas regras ajudam a identificar padrões de compra e podem ser usadas para organizar prateleiras, sugerir produtos ou estimular vendas em supermercados e outros contextos comerciais.
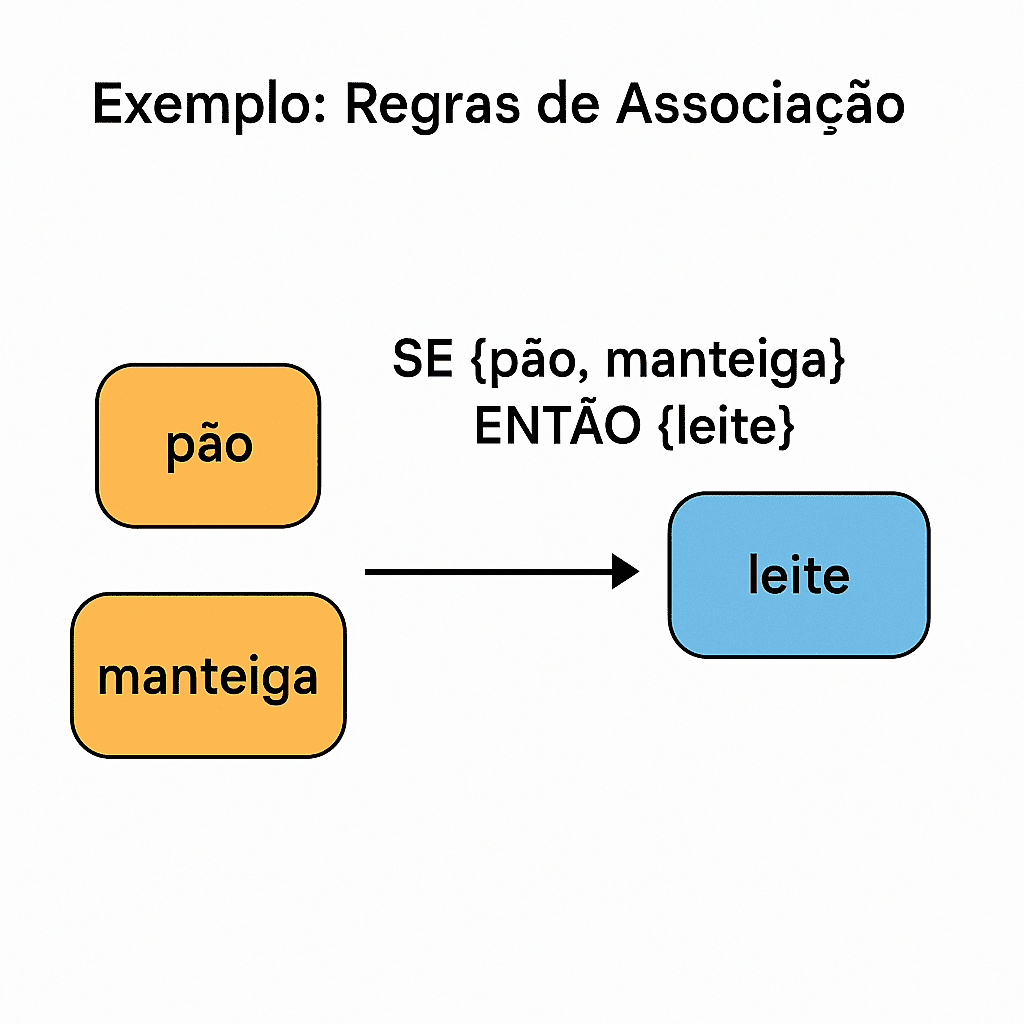
Exemplo (da imagem):
SE {pão, manteiga} ENTÃO {leite}
Significa que quando os clientes compram pão e manteiga, é comum também comprarem leite.
Para que uma regra de associação seja relevante, ela deve atender a duas medidas principais:
- Suporte: indica com que frequência a regra ocorre no banco de dados, ou seja, a proporção de transações em que X e Y aparecem juntos.
- Confiança: mede a força ou certeza da relação, representando a probabilidade de Y ocorrer dado que X ocorreu (P(Y|X)).
Em resumo, o suporte mostra a frequência e a confiança mostra a força da regra.
Cai em prova:
(Ministério da Economia) A técnica de associação é utilizada para indicar um grau de afinidade entre registros de eventos diferentes, para permitir o processo de data mining.
✅ Verdadeiro.
Classificação
A classificação é uma atividade humana natural — buscamos organizar e compreender o mundo dividindo objetos e seres em categorias.
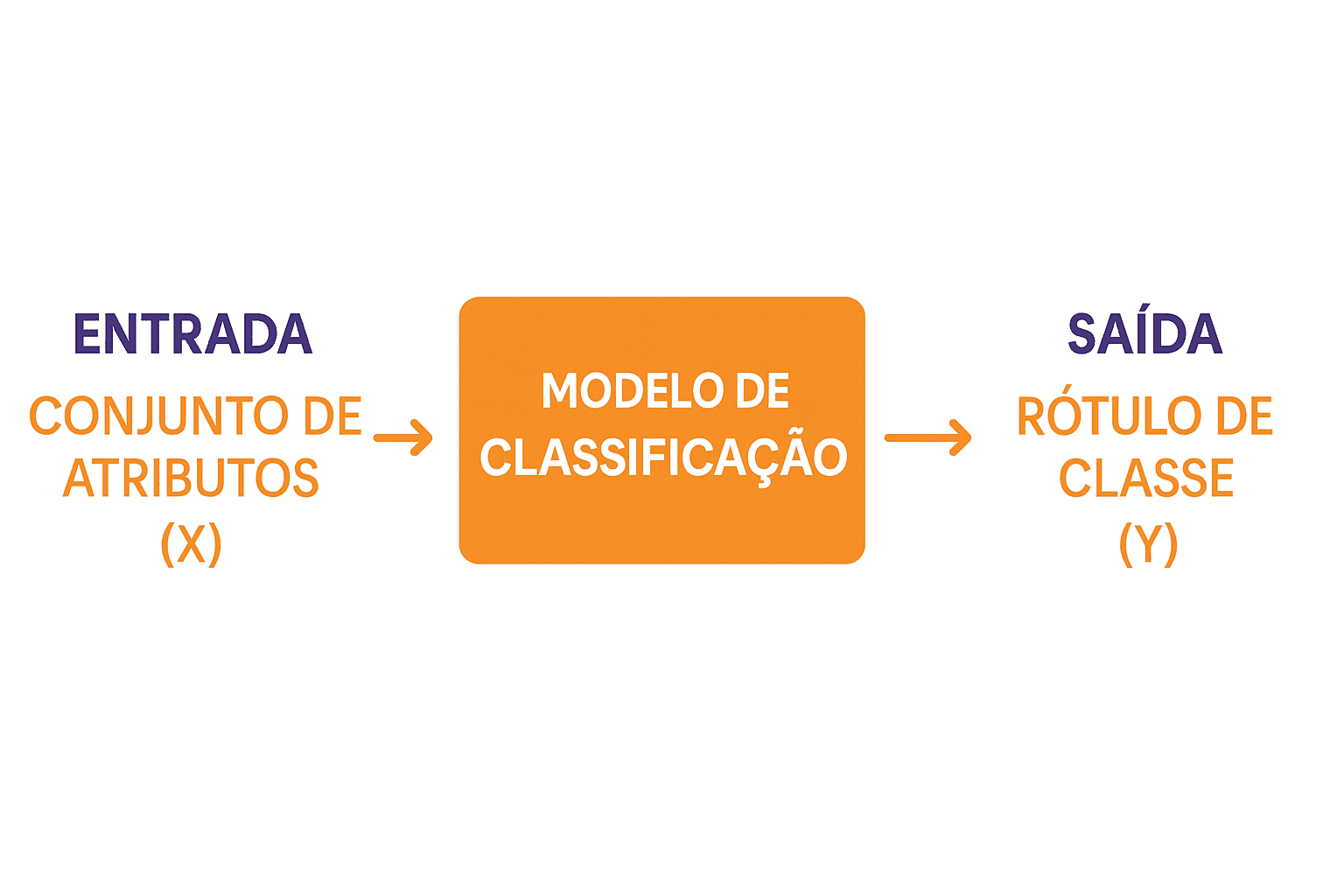
Em mineração de dados, essa tarefa consiste em atribuir um novo objeto a uma das classes predefinidas, com base em exemplos já classificados.
Formalmente, a classificação é o aprendizado de uma função que relaciona atributos (x) a um rótulo de classe (y), permitindo prever a categoria de novos dados.
Agrupamento (CLUSTERING)
A análise de clusters (ou agrupamento) é uma técnica de aprendizado não supervisionado, usada quando as classes dos dados não são conhecidas.
Seu objetivo é encontrar grupos de objetos semelhantes entre si e diferentes dos demais, organizando os dados em conjuntos homogêneos.
Essa técnica permite descobrir padrões ocultos e facilitar a compreensão dos dados, sendo aplicada em áreas como pesquisa de documentos, biologia (genes e proteínas semelhantes) e finanças (estoques com variações parecidas).
Exemplo: ao analisar dados de precipitação no Brasil, o algoritmo pode agrupar regiões com padrões climáticos semelhantes, como o Nordeste seco e a Amazônia úmida.